Table of Contents
NVIDIA NVLink Spine: As artificial intelligence models grow exponentially in size and complexity, traditional data center networking technologies are hitting hard physical limits. To overcome this, NVIDIA has engineered one of the most advanced GPU interconnect architectures ever built — the NVLink Spine.
This technology is not just an incremental improvement. It represents a fundamental shift in how GPUs communicate at scale, enabling AI factories and supercomputers that operate faster than anything seen before.
What Is the NVIDIA NVLink Spine?
The NVLink Spine is a massive, ultra-high-bandwidth internal network that connects dozens of GPUs together as if they were a single, unified computing system.
Unlike traditional Ethernet or InfiniBand networks that rely on external switches and layered topologies, NVLink Spine is purpose-built for GPU-to-GPU communication with extreme bandwidth, ultra-low latency, and deterministic performance.
At its core:
- Every GPU can talk to every other GPU
- Communication happens at the same speed, regardless of distance
- The system behaves like one giant GPU instead of many separate ones
Inside the NVLink Spine: Explained by NVIDIA’s CEO
During a technical walkthrough, NVIDIA CEO Jensen Huang described the NVLink Spine in striking terms:
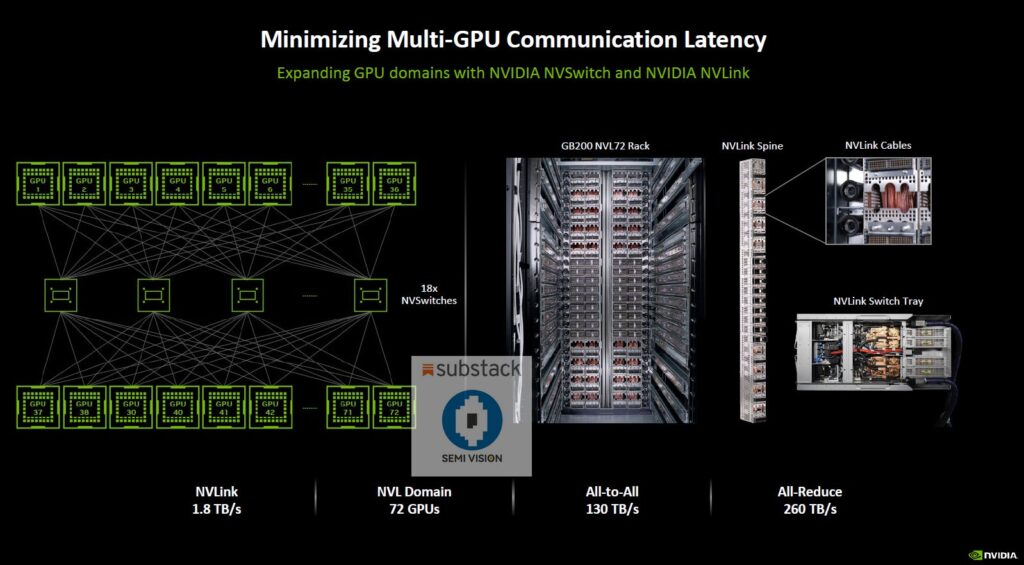
This is the NVLink spine. Two miles of cables, 5,000 cables — all structured, all coaxed, impedance-matched. It connects all 72 GPUs to all of the other 72 GPUs across this network called the NVLink switch.
The scale is unprecedented:
- ~5,000 precision-engineered coaxial cables
- ~2 miles of cabling inside a single system
- 9 NVLink switches forming the full spine
- 72 GPUs, each able to communicate directly with every other GPU
130 Terabytes per Second: More Traffic Than the Internet
The most jaw-dropping number is bandwidth.
The NVLink Spine delivers:
- 130 terabytes per second (TB/s) of total bandwidth
To put this into perspective:
- The peak traffic of the entire global internet is roughly 900 terabits per second
- Convert that to bytes (divide by 8), and the NVLink Spine moves more data than the entire internet — inside a single AI system
This level of bandwidth is critical for:
- Large language model (LLM) training
- Multi-trillion parameter AI models
- Real-time AI inference at massive scale
- Scientific simulations and digital twins
Why NVLink Spine Matters for AI and HPC
1. Eliminates GPU Bottlenecks
Traditional clusters slow down when GPUs wait on data. NVLink Spine removes this bottleneck by ensuring uniform, high-speed access across all GPUs.
2. Enables True Scale-Up AI
Instead of scaling out across thousands of networked servers, NVLink allows AI workloads to scale up inside a single system, dramatically improving efficiency.
3. Predictable Performance
Because every GPU communicates at the same bandwidth and latency, AI training becomes:
- Faster
- More stable
- Easier to optimize
4. Built for AI Factories
NVLink Spine is a cornerstone of NVIDIA’s vision of AI factories — data centers designed specifically to manufacture intelligence at scale.
“Technologies like NVLink Spine are part of a broader wave of AI infrastructure advancements. For more cutting-edge AI breakthroughs and industry insights, see our AI Innovation Showcase.”
NVLink vs Traditional Data Center Networking
| Feature | NVLink Spine | Ethernet / InfiniBand |
| GPU-to-GPU Bandwidth | Extremely High | Moderate |
| Latency | Ultra-Low | Higher |
| Topology | Fully Connected | Hierarchical |
| Performance Consistency | Deterministic | Variable |
| AI Model Scaling | Seamless | Complex |
The Future of AI Infrastructure
The NVLink Spine is more than a networking innovation — it is a physical manifestation of the future of computing.
As AI models continue to grow beyond trillions of parameters, systems like these will define who can train frontier models and who cannot. The combination of massive bandwidth, precision engineering, and full GPU connectivity positions NVIDIA years ahead in the AI infrastructure race.
Final Thoughts
The NVIDIA NVLink Spine demonstrates that the future of AI is not just about better algorithms — it’s about rethinking hardware from the ground up.
When a single internal network can move more data than the entire global internet, it becomes clear:
AI has entered the era of industrial-scale computation.